머신러닝은 '학습하는 동안의 감독 형태나 정보량'에 따라 학습 방법을 크게 3가지로 나뉜다.
- 지도 학습(Supervised Learning)
- 비지도 학습(Unsupervised Learning)
- 강화 학습(Reinforcement learning)
이번 포스팅에서는 간단하게 전체적인 개념만 살펴본다. 앞으로의 포스팅에서 자세하게 다룰 것이다.
지도 학습
훈련 데이터(Training data)를 알고리즘에 주입하고, 원하는 답인 레이블(Label)을 도출할 수 있도록 하는 기계학습의 한 방법이다.
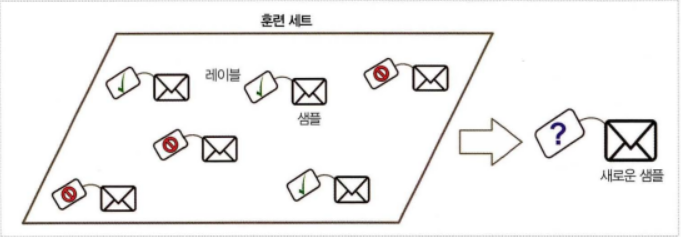
대표적인 지도 학습으로는 분류(Classification)와 회귀(Regression)가 있다.
분류(Classification)는 스팸 필터와 같이 많은 메일 샘플로 스팸인지 아닌지 훈련을 받은 후, 어떻게 새 메일을 분류할지 학습한다.
회귀(Regression)는 설명 변수를 두어 중고차 가격 같은 반응 변수(타깃)를 예측하는 것이다.
분류와 회귀는 뒤에 자세하게 다룰 것이며, 회귀의 경우 학부생때 배운 부분으로 자세하게 포스팅할 계획이다.
대표적인 지도 학습으로는
- k-최근접 이웃(k-nearest neioghbors)
- 선형 회귀(linear regression)
- 로지스틱 회귀(logistic regression)
- 서포트 벡터 머신(support vector machine)
- 결정 트리와(decision tree) 랜덤 포레스트(random forest)
- 신경망(neural networks)
등이 있다.
비지도 학습
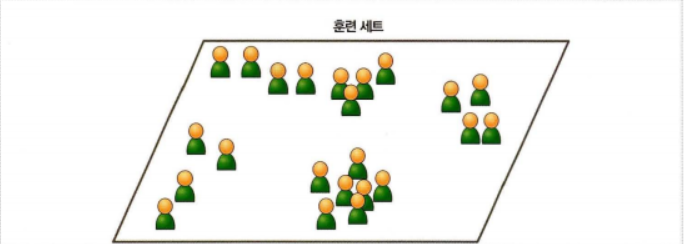
비지도 학습은 훈련 데이터(Training data)에 레이블(Label)이 없다. 입력값에 대한 목표치가 없다. 즉, 시스템이 아무런 도움 없이 학습해야 한다. 모델 스스로가 데이터의 규칙을 찾아내야 하며 데이터가 어떻게 구성되어 있는지를 알아내기 위한 학습이다.
대표적인 비지도 학습으로는
군집
- k-평균
- DBSCAN
- 계층 군집 분석
- 이상치 탐지와 특이치 탐지
- 원-클래스
- 아이솔레이션 포레스트
시각화와 차원축소
- 주성분 분석
- 커널
- 지역적 선형 임베딩
- t-SNE
연관 규칙 학습
- 어프라이어리
- 이클렛
등이 있다.
가볍게 몇 가지 알고리즘의 특징을 알아보도록 하자.
- 군집
군집에 대한 이해를 돕기 위해 블로그 방문자에 대한 데이터가 많이 있다고 가정하자.
비슷한 방문자들을 그룹으로 묶기 위해 군집 알고리즘을 적용하려 한다. 그러나 방문자가 어떤 그룹에 속하는지 알고르짐에 알려줄 수 있는 데이터 포인트가 없다. 그래서 알고리즘이 스스로 방문자 사이의 연결고리를 찾는다. 이를 통해 40%의 방문자가 만화책을 좋아하고 저녁때 블로그를 읽는 남성이며, 20%는 주말에 방문하는 SF를 좋아하는 젊은 사람임을 알게 될 수도 있다. 계층 군집 알고리즘은 각 그룹을 더 작은 그룹으로 세분화할 수 있기 때문에 각 그룹에 맞춰 블로그에 글을 쓰는 데 도움이 될 것이다.
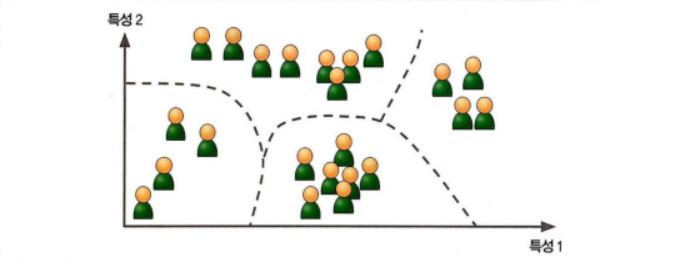
- 시각화
시각화 알고리즘의 경우 레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어준다. 이러한 알고리즘은 가능한 한 구조를 그대로 유지하려 하기 때문에 데이터가 어떻게 조직되어 있는지 이해 가능하고 예상치 못한 패턴을 발견할 수도 있다.
- 차원축소
차원축소는 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는 것이다. 상관관계가 있는 여러 특성을 하나로 합치는 것이다. 예를 들어 차의 주행거리는 연식과 강하게 연관되어 있기 때문에 차원 축소 알고리즘으로 두 특성을 차의 마모 정도를 나타내는 하나의 특성으로 합칠 수 있다. 이를 특성 추출(feature extraction)이라고 한다.
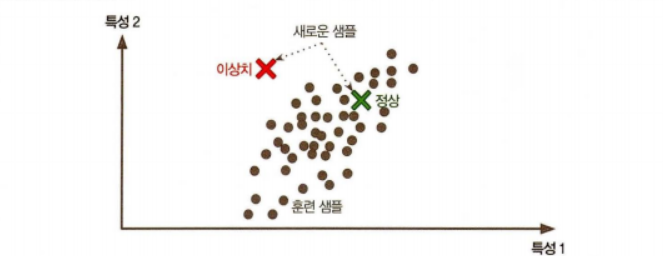
- 이상치 탐지
이상치 탐지 알고리즘의 경우 부정 거래를 막기 위한 이상한 신용카드 거래 감지, 제조 결함 감지, 학습 알고리즘 주입 전 데이터셋에서 이상치 감지 등에 사용된다. 시스템은 훈련하는 동안 대부분 정상 샘플을 만나 이를 인식하도록 훈련된다. 그 후 새로운 샘플을 보고 정상 데이터인지 혹은 이상치인지 판단하는 것이다.
- 연관 규칙 학습
연관 규칙 학습은 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 비지도 학습이다. 예를 들어 슈퍼마켓을 운영한다고 가정해보자. 판매 기록에 연관 규칙을 적용하면 바비큐 소스와 감자를 구매한 사람이 스테이크도 구매하는 경향이 있다는 것을 찾을 수도 있다는 것이다.
강화 학습
강화학습에서는 학습하는 시스템을 에이전트라고 부르며, 환경을 관찰해서 행동을 실행하고 그 결과로 보상이나 벌점을 받는다. 시간이 지나면서 가장 큰 큰 보상을 얻기 위해 정책이라고 부르는 최상의 전략을 스스로 학습한다. 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의한다.

보행 로봇이나 알파고 프로그램이 강화학습의 좋은 예이다. 특히 알파고는 수백만 개의 게임을 분석해서 승리에 대한 전략을 학습했으며 자기 자신과 많은 게임을 했다. 그리고 세계 챔피언과 게임할 때는 학습 기능을 끄고 그동안 학습했던 전략을 적용한 것이다.
'ML' 카테고리의 다른 글
| Zero-Shot Learning (0) | 2023.12.09 |
|---|---|
| [핸즈온 머신러닝 정리] 1장. 배치 학습과 온라인 학습 (0) | 2021.06.26 |

